

隨著大型語言模型(LLM)的應用日益普及,許多企業與開發者選擇使用如 Ollama 等框架,在本機電腦桌機、筆電,或包括地端伺服器、NAS 等設備建構的私有雲環境中部署 AI 模型,以期在保有資料隱私的同時,也能享受 AI 帶來的便利。然而,方便的部署流程其實也已經埋下了安全隱患。
日前由 Cisco 研究員 Dr. Giannis Tziakouris 與 Elio Biasiotto 發表在 Cisco 官方部落格的文章「Detecting Exposed LLM Servers: A Shodan Case Study on Ollama」中,引發了業界關注,他們揭露了全球有超過 1,100 台 Ollama 伺服器 (實際上可能更多),因資安方面的配置不當,而直接暴露在公開網路上。更令人擔憂的是,當中有高達將近兩成的伺服器無需任何身分驗證,即可被任意存取。
Shodan 上的驚人發現
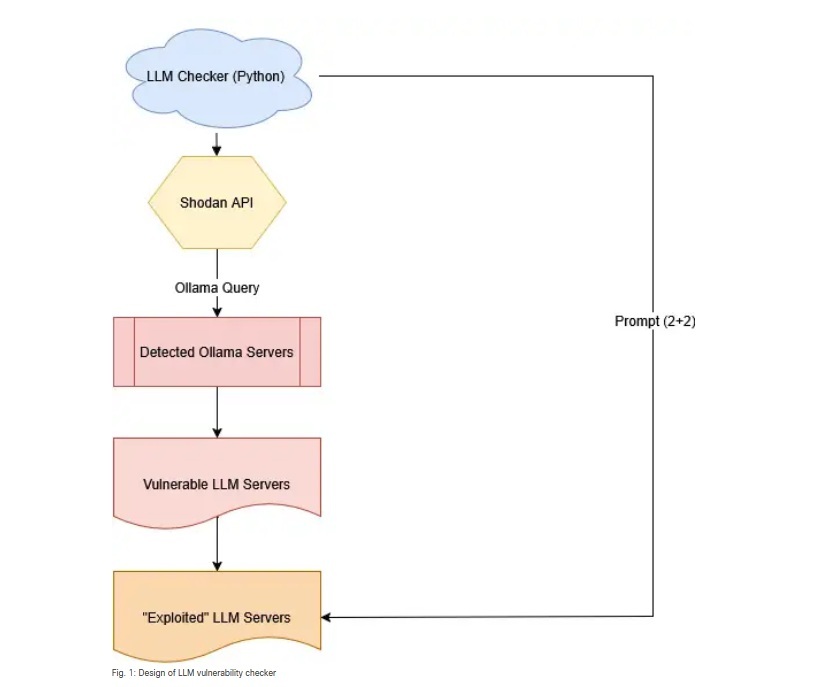
Cisco 的研究團隊利用業界常查找服務是否曝險的搜尋引擎 Shodan,針對執行 Ollama 框架的伺服器進行掃描。Ollama 因其易用性與本地部署的特性,廣受開發者社群歡迎,但也正因如此,許多使用者在部署過程中,忽略了基本的安全設定。
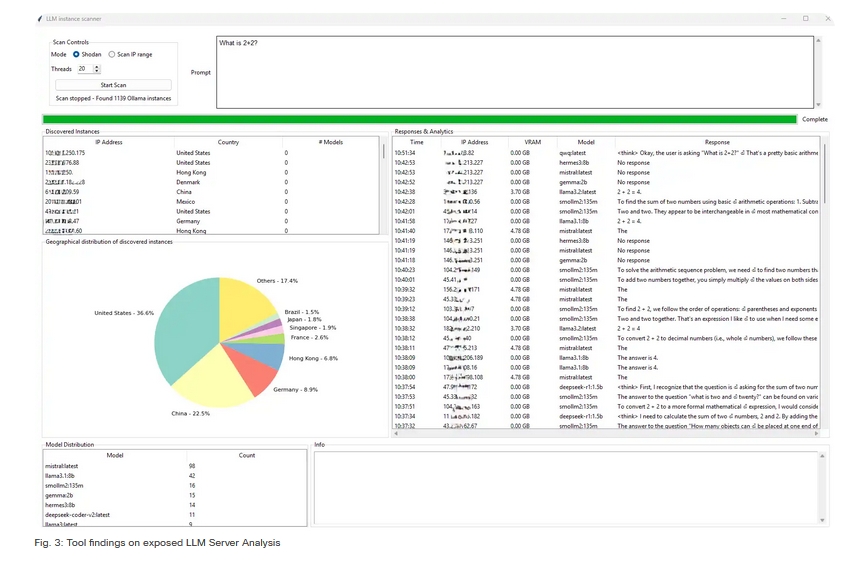
研究發現,這些暴露的伺服器最多分布在美國 (36.6%)、中國 (22.5%) 與德國 (8.9%),這些曝險伺服器普遍存在以下問題:
1、預設選項沒改的風險,許多使用者直接採用 Ollama 安裝好後的預設選項,並沒有去限制可存取服務的 IP 位址,導致伺服器對整個網際網路開放。
2、缺乏身分驗證,在預設情況下,Ollama 的 API 端點並未強制要求身分驗證,這意味著任何知道伺服器 IP 位址的人,都能直接與其互動。
3、網路隔離不足,開發者可能在內部網路中設定 Ollama,但未妥善設定防火牆或網路 ACLs,導致內部服務意外地暴露於公開網路。
曝險伺服器所帶來的潛在威脅
一台無須驗證即可存取的 LLM 伺服器,可能將帶來幾種嚴重的安全風險,比方說 :
資源濫用,攻擊者可利用這些免費的運算資源,進行加密貨幣挖礦、發動DDoS攻擊,或作為其惡意活動的跳板。
惡意提示注入 (Prompt Injection),攻擊者可透過特製的提示,繞過模型原有的安全限制,使其產生有害、不實或偏頗的內容。若模型曾使用敏感或專有資料進行微調,攻擊者便可能透過巧妙的提問,反推出模型的訓練資料,導致機敏資訊外洩,在更複雜的攻擊情境中,這些曝險的 LLM 伺服器,可能成為滲透企業內部網路的破口。
Cisco 更指出,這些曝險的伺服器不只是 Ollama ,還包括下列等知名服務,並將相關的預設連接埠列出來:
Ollama / Mistral / LLaMA models — Port 11434
vLLM — Port 8000
llama.cpp — Ports 8000, 8080
LM Studio — Port 1234
GPT4All — Port 4891
LangChain — Port 8000
如何防範與自保
Cisco 的這份報告,不僅揭示了問題,也提醒所有正在使用或計畫部署本地LLM的使用者,應立即檢視並強化自身的安全設定,該公司專家也提供了幾點建議:
詳閱官方安全文件:在部署任何應用程式之前,務必詳閱其安全設定指南,切勿完全依賴預設選項。
限制存取權限:設定防火牆規則,將 Ollama 伺服器的存取權限,限制在受信任的 IP 位址範圍內。
啟用身分驗證:為 API 端點增加身分驗證機制,確保只有經過授權的使用者,才能與模型互動。
定期進行安全審核:定期使用 Shodan 等工具,從外部視角檢視自身的網路資產,確保沒有服務意外暴露。
CyberQ 觀點 : 企業應落實 ISO 27001 資安合規性要求
Cisco 的這項研究,再次凸顯了在追求快速部署與功能實現的同時,絕對不能輕忽基本資安配置的重要性。對於所有開發者與維運人員而言,在享受 AI 帶來便利的同時,我們也必須為其安全性負起責任。
我們日常進行 ISO 27001 資安合規性要求時,除了落實外,定期檢視必要的防火牆選項,既有服務設定是否安全 ? 還有哪些服務曝險? 可說是資安方面的日常。在 AI 相關應用蓬勃發展,但 AI 相關攻擊也變多的時局下,落實資安合規性,是我們進行相關服務該有的基本。
首圖採用 Google Gemini AI 生成








