

中國人工智慧新創公司 DeepSeek (深度求索),在相隔將近五個月後,再次大幅更新了他們的 V3 基礎模型,推出了 DeepSeek V3.1。這次升級的亮點,在於它具備了針對中國本土製造晶片的最佳化功能,同時處理速度也更快了。
DeepSeek 對外指出,V3.1 模型採用了 UE8M0 FP8 精度格式。他們特別提到,這種格式是專門為「即將問世的下一代本土晶片」設計的。不過,該公司並沒有明確說明這項新功能具體支援哪些晶片型號或製造商。
模型進化與核心技術改善
這次是 DeepSeek 近期第三度進行模型更新。他們在今年三月先做了 V3 的早期強化,接著五月又發布了 R1 模型升級。DeepSeek-V3.1 對於分詞器和聊天模板(chat template) 做了大調整,與 DeepSeek-V3 有明顯區別。
新版本的核心特色是採用了全新的混合推論架構,讓模型能在同一框架下同時支援「思考」模式(Think)與「非思考」模式。相較於其 R1 推論模型,V3.1 Think 模式能更快給出答案。
透過後訓練的最佳化,新模型在使用工具和執行代理任務方面的表現有顯著提升,甚至在 Aider 多語言程式編碼基準測試中,得分還超越了 Anthropic 的 Claude 4 Opus。
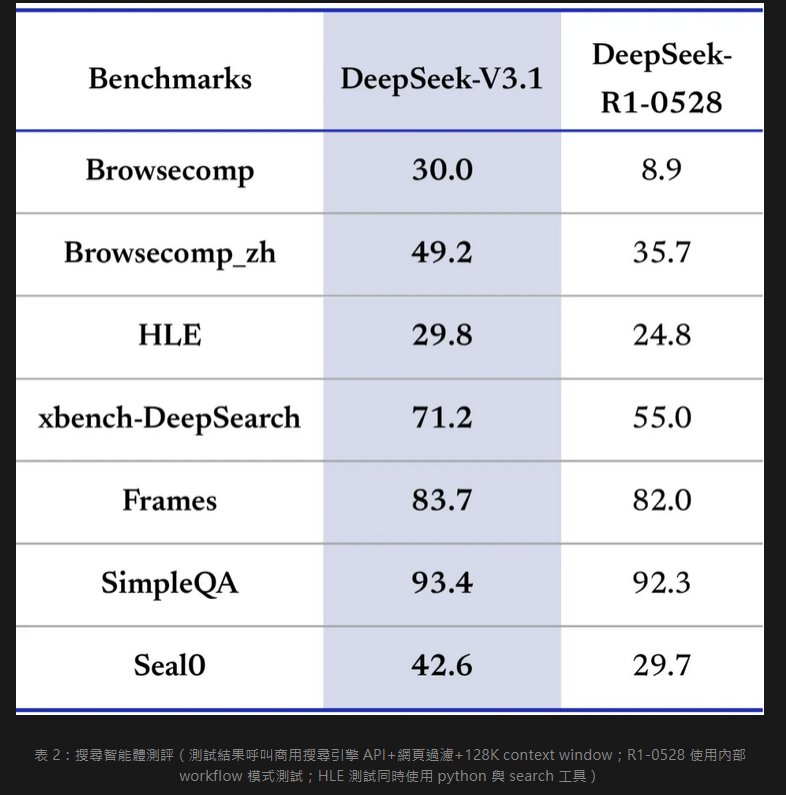
DeepSeek 表示,經過思維鏈壓縮訓練後,V3.1-Think 在輸出 Token 數量減少 20% 到 50% 的情況下,各項任務的平均表現仍與該公司之前發表的 R1-0528 版本差不多;而且在多項搜尋代理測試中表現更大幅提升,超越了 R1-0528。
API 更新與市場策略調整
目前,DeepSeek 官方的 App 和網頁版模型都已同步升級到 V3.1。此外,DeepSeek API(應用程式介面)也同時升級,相關文件說明於此,且上下文記憶容量全面擴展到 128K。這代表模型現在能處理更多資訊,具備更強大的記憶能力。新版本同時也新增支援 Anthropic API 格式,以簡化開發者從其他平台轉換過來的流程。
DeepSeek 聲明 V3.1 模型使用的 UE8M0 FP8 精度格式是針對下一代中國本土晶片所設計。據了解,UE8M0 FP8 並非 NVIDIA 官方的 FP8 標準,而是其一種變體格式。目前支援 FP8 的主要是 NVIDIA H 系列和 B 系列,而中國本土晶片中也已有明確支援 FP8 的產品問世。
國外媒體引述分析指出,DeepSeek 對中國本土晶片相容性的重視,可能顯示隨著北京在美國華府出口限制下持續開發美國技術的替代品,DeepSeek 正將其 AI 模型與中國不斷發展的半導體生態系統能接續起來。
另一方面,DeepSeek 宣布將於 9 月 6 號起實行新的 API 定價方案,並取消夜間優惠。外界普遍認為,這代表著在服務能力擴大後,慢慢開始走向商業化。
我們實際上去測試 API ,可以發現他們的價格競爭力還是有的,預估近期各大 AI 公司的 API 價格策略會有一番調整以符合市場競爭。








